Solving Wordle - Novel Strategies for the NP hard problem
Wordle is the popular game where you try to guess a hidden word in guesses.
Each guess you get a pattern consisting of black, yellow and green colours for each letter of the guess.
A guess of “PARSE” would return a hint with a pattern, like this:
Terminology
| Word | Meaning |
|---|---|
| Hidden word | A word that could be the answer, but it is hidden from the player |
| Test word | A word that can be used as a guess |
| Pattern | The hint given by the game after making a guess |
| “Easy” mode | The original game where the set of test words is not restricted |
| “Hard” mode | A variation where the set of test words gets smaller depending on the previous guesses and patterns. In this variation, you can only use guesses that match the patterns provided |
Results
The regular wordle list from 15-Feb-22 has hidden words , and test words .
The regular wordle problem has been looked at in great depth by Alex Selby on The best strategies for Wordle, part 2.
BIGHIDDEN mode, which is a harder version where there are hidden words and test words, is what I focused on. In particular, the wordle “easy” mode, which is ironically harder to compute than wordle hard mode, where the test words you can use are restricted by your previous guesses.
With BIGHIDDEN mode, it can be proven (by verifying the models) that there are at least unique starting test words that have a solution. Unless there are mistakes in the code, there should be exactly unique starting test words for this problem, because it was exhaustively calculated.
Finding the solution is quite difficult, but verifying that it is a correct solution is simple. The complete 6460 word list is available here, and the all the models are here.
Using solve from domsleee/wordle.
| Goal | Command |
|---|---|
| Find all solutions | ./bin/solve --guesses ext/wordle-combined.txt --answers ext/wordle-combined.txt |
| Verify a model | ./bin/solve --guesses ext/wordle-combined.txt --answers ext/wordle-combined.txt --verify model.json |
New strategies
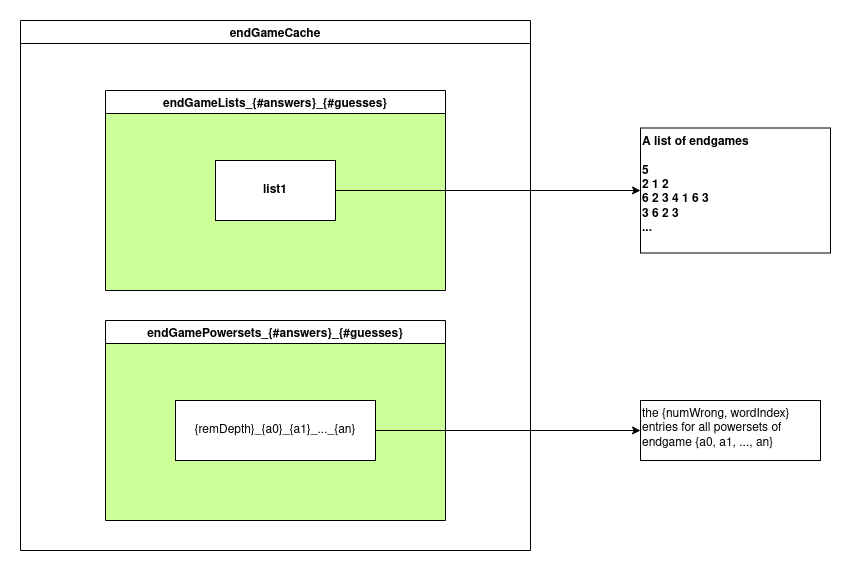
1. EndGame Db
Refer to EndGameAnalysis/ folder.
This is a cutoff that caches all powersets of sets of words . Currently it uses 2276 sets of words that match on 4 letters + positions, e.g. pattern .arks.
2. Lower bounds using a cache entry that is a subset
The main idea is that if you are querying for a lowerbound for a set of hidden words when you have known lower bounds for sets of hidden words :
This only makes sense for easy mode, since for hard mode you would also need to consider the test words.
In terms of implementation details, I tried an inverted index approach SubsetCache.h, and also a trie approach.
3. Most solved in 2 or 3 guesses
See this PR.
We know the following
- 2 guesses ⇒ any 3 words can be solved (by exhaustion)
- 3 guesses ⇒ any 5 words can be solved (reasoning, {1,1,1} can add any 2)
normal: bin/solve --guesses ext/wordle-guesses.txt --answers ext/wordle-answers.txt
bighidden: bin/solve --guesses ext/wordle-combined.txt --answers ext/wordle-combined.txt
--other-program |
normal | bighidden |
|---|---|---|
any3in2 |
✅ | ✅ |
any4in2 |
❌ (13 groups, eg batch,catch,hatch,patch) | ❌ (11423 groups) |
any6in3 |
✅ | ❌ (eg fills,jills,sills,vills,bills,zills) |
4. Remove guesses that have a better guess
Refer to RemoveGuessesBetterGuess/
Goal: reduce the size of test words by removing test words that have a better test word.
Let be the partitioning of the hidden word set using test word , i.e.
Where is the words in which would give pattern when guessing the word .
Define to mean is at least as good as if every partition of is a subset of a partition of :
implies that can be deleted from .
proof
Consider this definition of solvability, which returns iff there is a solution in guesses:
We want to prove that will return an equivalent value if we remove values from .
For every that is used as a better guess than :
We can prove this by cases:
If any value of the RHS is , the claim is clearly true because the domain is .
If all values of the RHS is , then all values of the LHS is because every partition of the LHS is a subset of a partition on the RHS.
qed
For least possible guesses
The definition for least possible guesses, taken from The best strategies from Wordle:
The same definition for “better guess” doesn’t work because the sum can exclude a partition () . So for least guesses, we must add an additional check that .
Approximation
This is nice however I could not find a fast enough way of doing this.
Using the partitioning approach, I could find an algorithm, but with a reasonable approximation, there is an approach. Typical values are and .
An approximation of this partitioning check is to reason about which partitions would be split, by reasoning about how two words of are differentiated:
1 Non-letter rule
If a letter does not occur in any word of , then any occurrence of that letter in a test word will not differentiate any two words of .
2 Green letter rule
If every position of one letter across all has the same position in every word of (for all positions of the letter in the word), then any occurrence of that letter in a test word will not differentiate any two words of .
3 exactly-n letter rule (yellow letter rule)
If there are exactly occurrences of in every word in , then any occurrence of in that is in a position other than all the positions of in can be ignored.
- If there are at most two in every word in , and one of them is green, the same rule does not apply
- reason: for guess , 1Y gives no information when has but gives information when has . Example: from implies has
4 most-n letter rule
If there are at most occurrences of in every word in , a word with of can mark up to positions that don’t occur in any position of - they are guaranteed to be useless
5 least-n letter rule
If there are at least occurrences of in every word in , a word with with of can mark all letters that don’t occur in any position of - they are guaranteed to be useless